# 시계열 예측 : Time - Series - Forecasting
- 과거의 시계열 데이터를 토대로 미래의 시계열데이터를 예측하는 것
- 주로 정량적 데이터에 대한 정량적 예측을 의미함
# 시계열 예측의 중요성
- 미래를 위한 전략 수립 / 적용분야가 다양함 / 비즈니스 의사 결정에 활용
# 시계열 예측이 어려운 이유
- 예측의 불확실성 / 데이터의 노이즈 / 패턴의 다양성 / 다변량 시계열의 존재
# 시계열 예측 프로세스
1) 데이터 수집 및 전처리 : 누락된 데이터나 이상치를 처리하고 정규화하여 데이터 준비
2) 시각화와 탐색적 데이터 분석(EDA) : 그래프나 통계적 분석을 통해 시각화 / 데이터 특성 이해
3) 예측 모형 선택 : ARIMA / SARIMA / Prophet / LSTM / GRU등 다양한 모델 중 적합한 모델 선택
- ARIMA : auto regressive integrated moving average
- SARIMA : seasonal ARIMA
- Prophet : 페이스북 개발 / 시계열 예측을 위한 오픈소스 라이브러리 / 추세,계절성,휴일효과 자동고려
/ 결측치 이상치에 어느정도 강건함 / 파라미터가 직관적이라 해석 쉬움 / python과 r모두 지원
- LSTM : long short term memory / RNN의 한 종류 / RNN의 장기 의존성(기억이 희미해지는)문제를 게이트구조로 해결
- GRU : gated recurrent unit / LSTM과 같은 RNN계열의 딥러닝 모델 / LSTM보다 더 가벼움 -> 학습속도 빠름 성능 비슷
4) 예측 모형 학습
5) 모델 평가 : RMSE, MAE, R-squared와 같은 평가지표 사용
* RMSE : root mean squared error / mae : mean absolute error / r-squared : 결정계수
6) 예측 적용 : 예측 구간과 신뢰 구간을 고려하여 결과를 해석하는 것이 중요함
# 시계열 예측 모형의 역사

# 시계열 예측의 평가
1. 시계열 예측의 평가 방법
- 예측값의 평가는 오차를 측정하여 수행함
- 예측값은 미래에 대해서만 존재함 -> 데이터를 학습데이터와 평가데이터로 분리함
* 통상적으로 비율은 8:2 but 예측시평을 고려하여 결정함(평가데이터크기 >= 예측시평)
* 예측시평이 짧은 단기예측의 경우에는 Rolling Horizon(한 기간씩 이동하며 평가)으로 평가함

2. 예측의 평가구간
- 시계열 예측은 주기적으로 시행함
* 데이터의 크기를 동일하게 사용하면 Rolling / 누적된 모든 데이터를 사용하면 Expanding
- 예측의 평가구간은 예측값과 실제값을 비교하는 구간임
* 시평기간의 예측성능이 중요하므로, 예측의 평가구간은 시평을 사용함
* validation 데이터나 Test데이터의 크기가 시평보다 크다 -> Rolling Horizon을 사용
* validation 데이터나 Test데이터의 크기가 시평보다 작다 -> 전체 구간에 대하여 평가함

# 성능평가 지표 : 오차(e)에 대한 다양한 지표로 평가

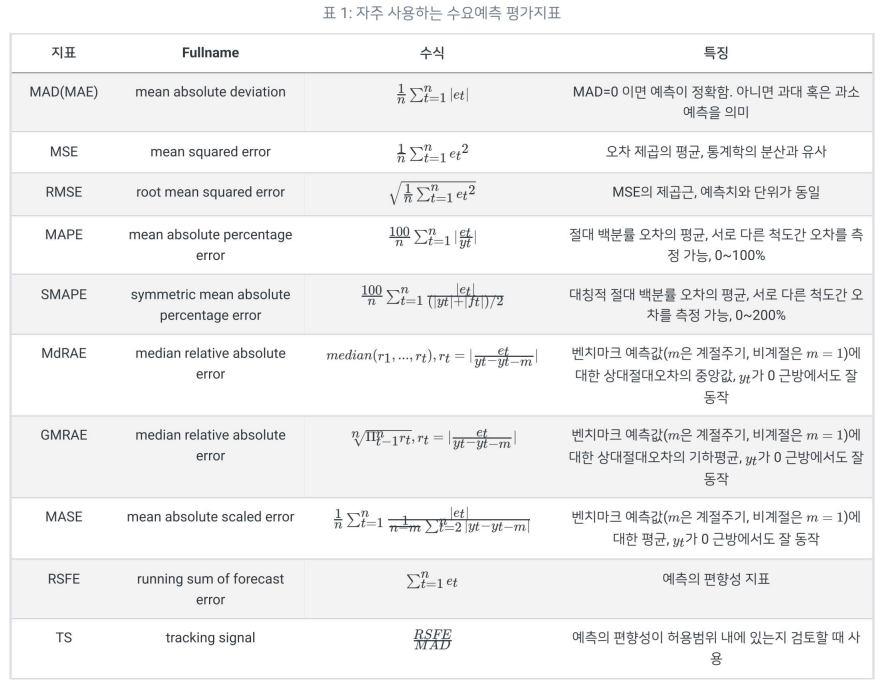
* 어느것이 더 좋은 평가지표인가?

* 지표해석 예시

# Sktime 라이브러리의 시계열 예측 평가지표
- 클래스는 CamelCase로 작성되어 있고 객체를 생성해서 사용해야 함 / 함수는 snake_case로 작성되어 있고 함수를 호출
# sktime 시계열 평가지표 클래스 및 함수 사용
import pandas as pd
import sktime.performance_metrics.forecasting as sktm
from sktime.performance_metircs.forecasting import mean_absolute_percentage_error as MAPE
ts = pd.Series([10, 15, 9, 12, 8, 11, 14, 13, 10, 12])
ts_pred = pd.Series([10, 12, 8, 11, 14, 13, 10, 9, 15])
# 클래스 사용 : 객체 생성
mape = sktm.MeanAbsolutePercentageError()
print(f'{mape(ts, ts_pred) = }')
# 함수 사용
print(f'{sktm.mean_absolute_percentage_error(ts, ts_pred) = }')
print(f'{MAPE(ts, ts_pred) = }')
# sktime에서 제공하는 평가지표
import pandas as pd
from sktime.utils.plotting import plot_series
from sktime.performance_metrics.forecasting import mean_absolute_error as MAE
from sktime.performance_metrics.forecasting import median_absolute_error as MdAE
from sktime.performance_metrics.forecasting import mean_squared_error as MSE
from sktime.performance_metrics.forecasting import median_squared_error as MdSE
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error as MAPE
from sktime.performance_metrics.forecasting import median_relative_absolute_error as MdRAE
from sktime.performance_metrics.forecasting import geometric_mean_relative_absolute_error as GMRAE
from sktime.performance_metrics.forecasting import mean_absolute_scaled_error as MASE
ts = pd.Series([97, 102, 80, 100, 90, 120, 110, 120, 130, 140])
ts_pred = pd.Series([95, 105, 90, 110, 85, 115, 110, 125, 135, 145])
# ts_pred를 한 시점씩 이동하고 결측치는 마지막 값으로 대체
ts_bench = ts_pred.shift(1).bfill()
# 시계열을 시각화
plot_series(ts, ts_pred, ts_bench, labels=["ts", "ts_pred", "ts_bench"])
print(f'MAE(ts, ts_pred) = {MAE(ts, ts_pred) :.4f}')
print(f'MdAE(ts, ts_pred) = {MdAE(ts, ts_pred) :.4f}')
print(f'MSE(ts, ts_pred) = {MSE(ts, ts_pred) :.4f}')
print(f'MdSE(ts, ts_pred) = {MdSE(ts, ts_pred) :.4f}')
print(f'MAPE(ts, ts_pred, symmetric=True) = {MAPE(ts, ts_pred, symmetric=True) :.4f}') # SMAPE
print(f'MdRAE(ts, ts_pred, y_pred_benchmark=ts_bench) = {MdRAE(ts, ts_pred, y_pred_benchmark=ts_bench) :.4f}')
print(f'GMRAE(ts, ts_pred, y_pred_benchmark=ts_bench) = {GMRAE(ts, ts_pred, y_pred_benchmark=ts_bench) :.4f}')
print(f'MASE(ts, ts_pred, y_train=ts_bench) = {MASE(ts, ts_pred, y_train=ts_bench) :.4f}')
print(f'RSFE = {(ts - ts_pred).sum() :.4f}')
print(f'TS = {(ts - ts_pred).sum()/MAE(ts, ts_pred):.4f}')
'시계열분석' 카테고리의 다른 글
| 시계열분석(w3) - sktime라이브러리 (0) | 2025.03.27 |
|---|---|
| 시계열분석(w3) - 시계열 데이터 처리 (0) | 2025.03.25 |
| 시계열분석 - 시계열데이터 수집 (1) | 2025.03.17 |
| 시계열분석w1 - 시계열분석 개요 (0) | 2025.03.10 |