# 시계열 데이터(time series data) : 시간에 따라 순차적(sequence)으로 관측한 시퀀스데이터
# 시퀀스 vs 시계열
- 시퀀스(sequence)데이터
1) 순서가 있는 데이터
2) 순서만 중요하고 시간적인 “절대 영점”이 없음
- 시계열(time series)데이터
1) 시간에 따라 순차적으로 관측한 시퀀스 데이터
2) 데이터의 순서 뿐만 아니라, 관측(발생) 시간이 중요한 의미를 가짐 -> 무언가가 발생한 시점이 언제냐
3) 시계열 데이터는 시간적인 “절대 영점”이 존재함
4) 사건(event)과 연계하여 분석에 활용됨
# 시계열 데이터의 중요성
- IOT(internet of things, 사물인터넷) 기술의 발전으로 다량의 센서로부터 다량의 시계열 데이터가 생성되고 있음
- 데이터 분석의 주요 목적 중 하나는 “과거 데이터를 활용한 미래를 예측”하는 것이므로 이러한 부분에서 시계열 데이터가 매우 중요함
* ML : 수학적 모형을 알고있음 / DL : 모형이 없고 뉴런을 활용한 범용구조 생성 -> 데이터로 모형을 깎는것
* XAI : explanable AI(설명가능한 인공지능)
* Transfer Learning : 기존에 학습시킨 모델을 재사용가능하게 하는것
# 시계열 데이터의 성분
- 체계적 성분(Systematic component)
1) 추세성분(trend component) : 관측값이 지속적으로 증가하거나, 감소하는 추세를 갖는 경우의 변동
2) 계절성분(seasonal component) : 주별 월별 계절별과 같이 주기적인 성분에 의한 변동 / 사이클(주기)가 일정함
3) 순환성분(cyclical component) : 주기적인 변화를 가지나, 변화가 계절에 의한 것이 아니고 주기가 긴 경우의 변동 / 주기가 일정하지 않음 -> 주기를 찾는것이 어려움 / ex) 경기순환..
- 불규칙 성분(irregular component)
1) 체계적 성분이 아닌 모든것
2) 백색잡음(white noise) / 무작위 잡음(random noise)
* random은 원인을 모르는것임 -> 원인을 알게되면 그부분은 불규칙성분이 아님

# 시계열 데이터의 유형
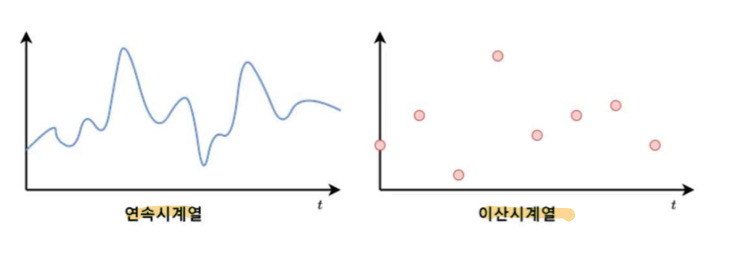
1. 연속 시계열(continuous time series) vs 이산 시계열(discrete time series)
- 데이터의 시간 간격에 따라 연속 시계열과 이산 시계열로 구분
- 연속 시계열 : 온도, 습도, 소리, 진동, 전압, 전류, 속도, 위치 등..
- 이산 시계열 : 일별, 월별, 분기별 판매량과 같이 일정한 시간 간격으로 집계된 데이터 or POS 데이터 or 로그 데이터와 같이 “이벤트가 발생할 때 관측된 데이터”
- 이산 데이터는 연속데이터의 일부분을 sampling한것임
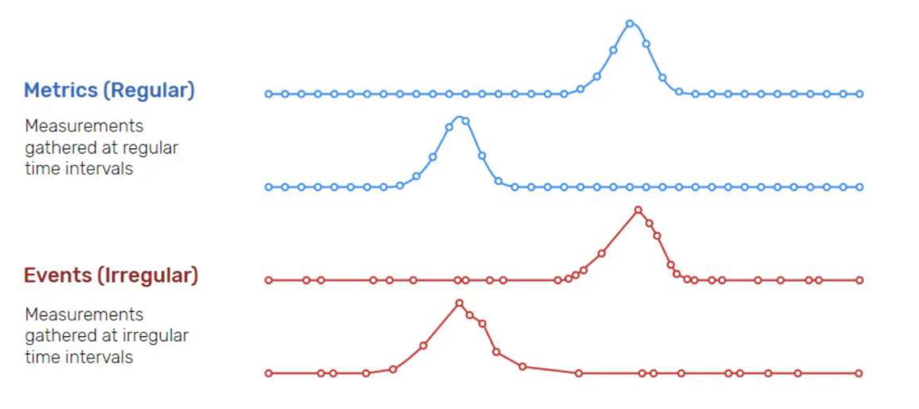
2. 측정 시계열(metrics / 모니터링 시계열) vs 사건 시계열(events / 상태 시계열)
- 데이터의 관측 방법에 따라 측정 시계열과 사건 시계열로 구분함
- 측정 시계열 : 상시 존재하는 특성치(변수)에 대해서 “일정한 시간간격(3분마다..)”으로 관측한 시계열 데이터 / ex) 센서 데이터, 네트워크 트래픽 데이터, 생체 신호 데이터 등
- 사건 시계열 : 특정 사건이 발생할 때 데이터가 생성되는 데이터 / 이벤트는 불규칙한 간격으로 발생하기 때문에 모델링하거나 예측할 수 없음 / ex) pos데이터, 서버 로그 데이터, 알람 데이터 등
* pos : point of sales
3. 주기 시계열(periodic) vs 비주기 시계열(aperiodic)
- 데이터의 반복성에 따라 주기 시계열과 비주기 시계열로 구분함
- 주기 시계열 : 일정한 주기를 가지고 동일한 패턴이 반복되는 시계열 / 다루기 쉬움 / 수학적 풀이 가능 / ex) 심박수, 모터의 진동 등
- 비주기 시계열 : 주기와 패턴이 변동되는 시계열 / 패턴은 있으나 크기와 주기가 달라짐 / ML & DL 적용분야

4. 단변량 시계열(일변량, 단일변량, univariate) vs 다변량 시계열(multi - variate)
- 분석의 대상이 되는 변수(관측치)의 개수에 따라 구분함
- 단변량 시계열 : 측정 변수가 1개인 것
- 다변량 시계열 : 측정 변수가 2개 이상인 것 / 측정 변수간 상관관계가 있음 / 일정한 시간 간격으로 측정된 다변량 시계열 데이터를 패널(pannel)데이터라고 함 -> 패널 데이터는 변수간 상관관계 있다고 판단안되어도 괜찮음 / 단변량 시계열을 피처 엔지니어링을 통해 (요일별, 월별, 분기별 등을 추가) 다변량 시계열로 변환하여 사용하기도 함

5. 정상성 시계열(stationary) vs 비정상성 시계열(non stationary)
- 시계열 데이터의 확률적 특성에 따라 정상성 시계열과 비정상성 시계열로 구분
- 정상성 시계열 : 시계열의 확률적인 특성(평균, 분산)이 시간에 따라 변하지 않음 / 약한 정상성을 띔
* 약한 정상성 : 평균이 상수(일정), 분산이 상수(일정), 자기공분산은 구간차에만 의존함(주기가 일정하다는 의미)
- 비정상성 시계열 : 시계열의 확률적인 특성이 시간에 따라 변함 / 추세, 진폭이 불안정하고 주기가 불안정한 시계열

* 상관계수 = 공분산 / 표준편차
* 회귀선 하에서의 등분산
# 시계열 분석의 목적
1. 데이터 축약(data compression)
- 데이터의 크기가 큰 시계열 데이터의 특성을 추출하여 축약함
* 특성 : 평균, 추세, 계절, 순환…
- 시계열 데이터는 일정한 시간간격으로 샘플링되기 때문에 데이터의 크기가 큼
* 시계열 데이터의 데이터의 크기가 크다 = 행의 개수가 많다
2. 시스템에 대한 이해(explanatory)
- 회귀분석을 통해 시간의 흐름에 따른 변수간 연관성의 “동적 특성”을 분석함(ex) 계절변동의 원인분석, 인구변화에 따른 경제활동의 변화, 기후변화에 따른 농작물 생산량의 변화등..)
- “시계열데이터 -> 주파수데이터”의 변환을 통해서 시스템의 “동적 특성”을 분석하고 이해함(ex) 모터의 진동에 따른 고장 예측)
- 시계열 데이터의 패턴을 분석하여 응용분야에 대한 통찰력을 제공함(ex) 스마트워치의 자이로 센서신호를 통한 동작 예측)
3. 미래에 대한 예측(forcasting)
- 과거의 패턴(평균, 추세, 계절)이 미래에도 계속된다는 가정하에 미래를 예측함(수요예측, 주가예측, 전력수요예측, 기후예측…)
# 시계열 분석의 절차
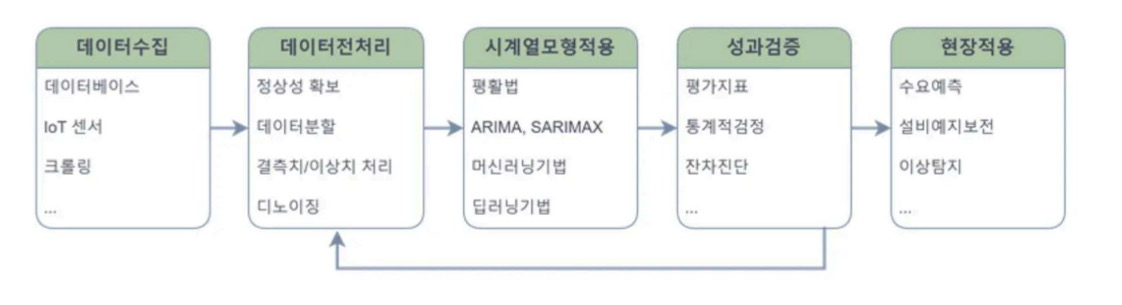
* 시계열 데이터의 데이터전처리는 정형데이터전처리와 다름 : 데이터를 삭제할 수 없음
* 평활법의 대표적인 사용처 : 수요예측
* 시계열에서는 평가지표가 유독 많음
* 디노이징이 매우 중요함
'시계열분석' 카테고리의 다른 글
| 시계열분석 - 07시계열예측개요 (0) | 2025.04.08 |
|---|---|
| 시계열분석(w3) - sktime라이브러리 (0) | 2025.03.27 |
| 시계열분석(w3) - 시계열 데이터 처리 (0) | 2025.03.25 |
| 시계열분석 - 시계열데이터 수집 (1) | 2025.03.17 |